Hello,欢迎来到我的Go语言学习笔记,这一篇我们一起来看看Go语言中一些常见错误,以及一些容易被人误解的地方。(另外,也欢大家迎浏览我的上一篇笔记:详解Go Testing😀)
为了突出问题,下面举的某些例子可能比较极端,还望大家不要纠结例子的使用场景,明白其中的错误原因即可。另外,欢迎大家补充示例🫵。
Bugs🐞
变量遮蔽(shadowing)🥷🏿
在 Go 中,变量遮蔽(variable shadowing)指的是在内部作用域中声明一个与外部作用域中同名的变量,从而覆盖了外部作用域中的变量。这种bug比较低级,但是可能会出现在比较负载的函数里,而且比较隐蔽,不容易被发现。
下面是一个简单的例子,findTarget从给定strs中查找第一个target,返回索引。但是这个简单的函数存在变量遮蔽的bug(到Go Playground运行),返回值永远是-1。
func findTarget(strs []string, target string) (i int) {
i = -1
for i := 0; i < len(strs); i++ {
if strs[i] == target {
break
}
}
return i
}
危险的map😈
未初始化
Go语言中未初始化的变量的值为此变量类型的默认值,map的默认值为nil,读值为nil的map是安全的,但是对nil的map进行写操作会引发Panic。(到Go Playround运行)
func main() {
var m map[string]int
// read from nil map, should not panic
println(m["a"])
// write to nil map, panic!!!
m["a"] = 1
println(m["a"])
}
并行读写map
Go语言的禁止多个goroutine同时读和写map(会引发Panic),因此如果有并行操作map的需求,必须使用锁。下面是一个在不加锁的情况下并行读写map的示例,程序会Panic(到Go Playground运行)。
package main
var m = make(map[string]int)
func consumer() {
for i := 0; i < 100000; i++{
_ = m["x"]
}
}
func producer() {
for i := 0; i < 100000; i++ {
m["y"] = i
}
}
func main() {
go consumer()
go producer()
select {}
}
但是Go允许多个goroutine并行读map,因此在读操作的性能要求较高时,可以优先考虑使用读写锁(sync.RWMutex);对写操作性能较高时,优先考虑写锁(sync.Mutex)。另外也可以使用封装好的支持并发操作的map(如sync.Map)。
难以捉摸的for循环🙉
意料之外的遍历结果
下面的示例遍历nums,并为每个num创建一个goroutine来打印num的值。期望的输出是打印[0,10),输出顺序不确定。(到Go Playground运行)。
func main() {
n := 10
nums := make([]int, n)
for i := 0; i < n; i++ {
nums[i] = i
}
// the output is not what you expect :(
for _, num := range nums {
go func() {
println(num)
}()
}
select {}
}
对于输出结果有没有感到意外?如果感到意外,说明你自己也可能会写出类型的代码。这段代码里存在一个Go语言的经典错误——循环变量捕获。在 Go 中,闭包(匿名函数)可以访问其外部作用域的变量。当闭包内部引用了外部作用域的变量时,实际上是对该变量的引用(而不是值的拷贝)。因此,如果在循环中创建了多个闭包,并且这些闭包共享了循环变量,那么它们实际上会共享相同的变量,而不是独立的副本。
修复上面的bug很简单,只需要让for里面的匿名函数接受一个参数即可,这样就能避免循环变量捕获错误了😀。(到Go Playground运行)
func main() {
// ......
// the output is what you expect :)
for _, num := range nums {
go func(num int) { // 这里声明需要一个参数
println(num)
}(num) // 传递for range遍历的num
}
// ......
}
意料之外的死循环
下面是一个从channel读取数据,然后处理的例子,很明显这段代码永远不会退出,但是当channel被关闭后,就会造成循环不会阻塞。可能会消耗大量资源(CPU、内存等)。(Go Playground完整例子)。
func consumer(c chan int) {
for {
select {
case n := <-c:
println(n)
// other case ......
}
}
}
这个错误的原因是对channel的操作不熟悉,读一个被closed的channel不会被阻塞,但是读channel可以用两个变量来接收结果,通过第二个变量判断是否读成功。因此这个代码改成下面这样就不会存在死循环了。(Go Playground完整例子)。
func consumer(c chan int) {
for {
select {
case i, ok := <-c:
if !ok {
println("channel closed")
return
}
println(i)
// other case ......
}
}
}
意料之外的内存泄漏
在实际开发过程中,经常有定时执行某个任务的需求。下面是一个定时执行任务的示例(worker),(完整代码到Go Playground运行)。
func worker1(c chan struct{}) {
count := 0
timeout := 0
for {
select {
case <-c:
count++
case <-time.After(1 * time.Second):
timeout++
}
}
}
这段代码看不出任何毛病,运行起来也OK,下面是这个需求的另一个版本(worker2),和worker1相比,worker2使用了time.NewTimer创建一个定时器。
func worker2(c chan struct{}) {
count := 0
timeout := 0
timer := time.NewTicker(1 * time.Second)
defer timer.Stop()
for {
select {
case <-c:
count++
case <-timer.C:
timeout++
}
}
}
这里给出这两段代码的完整示例,分别见work1和worker2。如果运行了worker1和worker2的完整示例,你会发现这两个代码的内存消耗差别很大,因为每次调用time.After都会创建一个time.Timer对象,且不会被GC回收,如果这段代码长时间在线上运行,就存在内存泄漏的问题。
跳不出的循环
Go语言中的break用于跳出for、select、switch作用的语句块,当for和select或switch结合时,要确保能按照预期跳出for循环体;(完整例子见Go Playground)
func worker(stopCh chan struct{}) {
println("worker start")
defer println("worker stop")
timer := time.NewTicker(1 * time.Second)
defer timer.Stop()
for {
select {
case <-stopCh:
println("stop signal received")
// just break the select!
break
case <-timer.C:
println("do something")
}
}
}
如果想跳出多重语句块,需要配合label使用,修正后的代码如下,(完整例子见Go Playground)。
func worker(stopCh chan struct{}) {
println("worker start")
defer println("worker stop")
timer := time.NewTicker(1 * time.Second)
defer timer.Stop()
loop:
for {
select {
case <-stopCh:
println("stop signal received")
// break the for loop
break loop
case <-timer.C:
println("do something")
}
}
}
defer
defer传参
defer关键字会使函数延迟执行,但是函数的参数是在执行defer的时候就被确定的。下面这个例子想在accumulate函数执行完之后记录一下sum值,但是defer记录的sum值永远是0。(到Go Playground运行)
func accumulate(nums []int) int {
var sum int
// log the sum
defer fmt.Printf("sum = %d\n", sum)
for _, num := range nums {
sum += num
}
return sum
}
要想通过defer记录真实的sum值,需要用到闭包(匿名函数),因为在闭包中引用外部变量时,会以引用的方式使用外部变量。(到Go Playground运行)。
func accumulate(nums []int) int {
var sum int
// log the sum
defer func() {
fmt.Printf("sum = %d\n", sum)
}()
for _, num := range nums {
sum += num
}
return sum
}
循环中使用defer
在循环中使用defer要慎重,比如下面这个示例,在打开文件不出错的情况下,循环无法结束,因此文件描述符也无法被及时释放。
func readFiles(c chan string) error {
for f := range c {
file, err := os.Open(f)
if err != nil {
return err
}
defer file.Close()
// do something with file
}
return nil
}
严肃对待生产环境👨✈️
JSON序列化与反序列化
一个完整的线上服务可能包含使用不同编程语言开发的组件,组件之间的数据交换有时会用到JSON,对于强类型的Go语言与弱类型的编程语言(如lua)之间传递JSON时需要格外小心。详见:编码为 array 还是 object。
下面是一段简单的lua代码,对空object做encode操作:
=== TEST 1: empty tables as objects
local cjson = require "cjson"
print(cjson.encode({}))
print(cjson.encode({dogs = {}}))
对于空的object,默认encode结果为{}。
{}
{"dogs":{}}
也可以设置将空object当作array处理,只需要设置一下即可:
=== TEST 2: empty tables as arrays
local cjson = require "cjson"
cjson.encode_empty_table_as_object(false)
print(cjson.encode({}))
print(cjson.encode({dogs = {}}))
输出结为:
[]
{"dogs":[]}
在lua中空对象,既可以序列化成object,也可以序列化成array,这种同一种数据可能生成不同结果的行为会让强类型语言很难做,因此Go语言遇到这种与期望类型不一致的数据时,Unmarshal时直接返回错误。
HTTP
确保HTTP client真正用了keep-alive
下面这个doRequest使用GET方法请求给定的url,如果频繁请求同一个url,并不会使用HTTP的keep- alive特性,要想使用keep-alive需要将HTTP的响应的Body读完并且关闭。(如果业务非常简单,无需处理响应的Body,也必须把Body读完,可以用io.Copy(io.Discard, resp.Body))。这里有一个完整的介绍案例:How To Reuse Http Connections In Go。
func doRequest(url string) error {
req, err := http.NewRequest(http.MethodGet, url, nil)
if err != nil {
log.Fatal(err)
}
resp, err := http.DefaultClient.Do(req)
if err != nil {
log.Fatal(err)
}
if resp.StatusCode != http.StatusOK {
return fmt.Errorf("status code is not 200, got: %d", resp.StatusCode)
}
return nil
}
http.Response.Body字段的注释中明确说明如果要复用HTTP1.x的keep-alive功能,需要将Body读完,切关闭Body。
// The http Client and Transport guarantee that Body is always
// non-nil, even on responses without a body or responses with
// a zero-length body. It is the caller’s responsibility to
// close Body. The default HTTP client’s Transport may not
// reuse HTTP/1.x “keep-alive” TCP connections if the Body is
// not read to completion and closed.
不使用HTTP的默认配置
HTTP client
http库中默认的HTTP client没有设置超时时间,HTTP client中的Timeout字段的超时时间是整个请求的超时时间(如下),因此在生产环境应该设置合理的超时时间。
- 建连时间;
- DNS解析;
- TCP三次握手;
- TLS握手(如果是TLS);
- 发送请求;
- 重定向(如果有);
- 读响应;
http.Client的Timeout字段源码:
type Client struct {
// ......
// Timeout specifies a time limit for requests made by this
// Client. The timeout includes connection time, any
// redirects, and reading the response body. The timer remains
// running after Get, Head, Post, or Do return and will
// interrupt reading of the Response.Body.
//
// A Timeout of zero means no timeout.
//
// The Client cancels requests to the underlying Transport
// as if the Request's Context ended.
//
// For compatibility, the Client will also use the deprecated
// CancelRequest method on Transport if found. New
// RoundTripper implementations should use the Request's Context
// for cancellation instead of implementing CancelRequest.
Timeout time.Duration
}
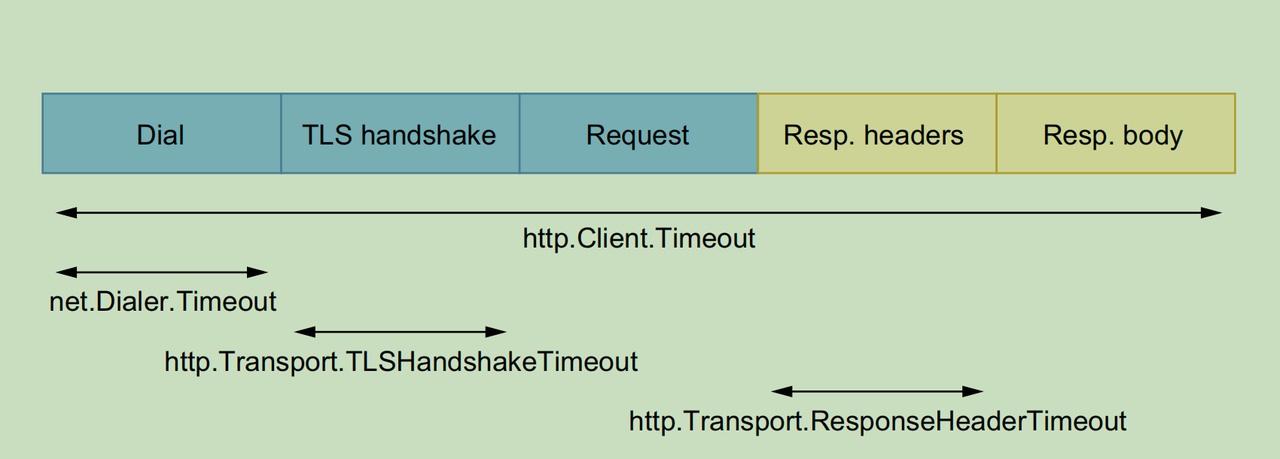
下面是一个自定义的HTTP client的示例,设置了各种超时时间(具体参数根据实际情况确定),还设置了最大空闲连接数等,HTTP client中还有很多参数,在程序调优时可能会用到。
client := &http.Client{
Transport: &http.Transport{
DialContext: (&net.Dialer{
Timeout: 5 * time.Second, // TCP 建联时间,默认3min
KeepAlive: 30 * time.Second, // keep alive 探测时间间隔,默认15s
}).DialContext,
MaxIdleConns: 100, // 最大空闲连接数(处于keep alive),默认值为2
IdleConnTimeout: 90 * time.Second, // keep alive保持最长时间,默认为0(无限制)
TLSHandshakeTimeout: 2 * time.Second, // TLS握手超时时间,默认不设置超时时间
ResponseHeaderTimeout: 2 * time.Second, // 发送完请求到收到响应头时间间隔,默认值为0
},
Timeout: 10 * time.Second, // HTTP请求超时时间,包括建连、发送请求、接收请求等
}
HTTP server
和HTTP client类似,默认的HTTP server很多默认的参数也不适合在线上环境运行,下面是一个简单的http.Server的定义(具体参数根据实际情况确定):
server := &http.Server{
Addr: "8080",
ReadTimeout: 10 * time.Second,
WriteTimeout: 10 * time.Second,
MaxHeaderBytes: 1 << 20,
}
类型断言
对interface进行类型断言时,如果类型不匹配就会触发panic。如下面这个示例第二次调用foo时传递一个string类型的参数就会导致程序Panic。(到Go Playground运行)
func foo(i interface{}) {
a := i.(int)
println(a)
}
func main() {
foo(1) // ok
foo("a") // panic
}
因此出于安全考虑,在做类型断言时,一般使用common ok的方式来接收返回值,通过第二个参数来判断类型是否符合预期。下面是调整过的foo函数,无论传递什么类型,foo都不会Panic。(到Go Playground运行)
func foo(i interface{}) {
a, ok := i.(int)
if !ok {
fmt.Printf("want type of int, got %T, %q\n", i, i)
return
}
println(a)
}
同样是类型断言,既可以用一个变量接收,也可以用两个变量接收。这其实是Go本身提供的语法糖,类型断言最终调用的是runtime.getitab,runtime.getitab的原型如下,Go编译器在编译源码时根据接收返回值的变量数量决定调用runtime.getitab时第三个参数是true还是false,如果用一个参数接收返回值,则canfail为true,如果类型不符合预期就会Panic。
func getitab(inter *interfacetype, typ *_type, canfail bool) *itab
禁用不安全的加密算法
Go的TLS使用的默认密码套件(cipher suites)包含了已经被认为不安全的加密算法(使用了DES和3DES,具体影响见CVE-2016-2183详情),如果对安全要求较高的场景,需要手动设置加密算法白名单,禁用加密算法DES和3DES。
// disable DES encrypt algorithm to avoid CVE-2016-2183
var CipherSuites = []uint16{
tls.TLS_RSA_WITH_RC4_128_SHA,
// tls.TLS_RSA_WITH_3DES_EDE_CBC_SHA,
tls.TLS_RSA_WITH_AES_128_CBC_SHA,
tls.TLS_RSA_WITH_AES_256_CBC_SHA,
tls.TLS_RSA_WITH_AES_128_CBC_SHA256,
tls.TLS_RSA_WITH_AES_128_GCM_SHA256,
tls.TLS_RSA_WITH_AES_256_GCM_SHA384,
tls.TLS_ECDHE_ECDSA_WITH_RC4_128_SHA,
tls.TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA,
tls.TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA,
tls.TLS_ECDHE_RSA_WITH_RC4_128_SHA,
// tls.TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA,
tls.TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,
tls.TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA,
tls.TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256,
tls.TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256,
tls.TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,
tls.TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,
tls.TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,
tls.TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,
tls.TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256,
tls.TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256,
// TLS 1.3 cipher suites.
tls.TLS_AES_128_GCM_SHA256,
tls.TLS_AES_256_GCM_SHA384,
tls.TLS_CHACHA20_POLY1305_SHA256,
}
版本信息
在业务发展的初期阶段,软件的CI/CD可能不完善,有时候需要频繁的人工操作。为了能区分同一个程序的不同版本,一般的做法是使用版本号来区分,但是有时候仅仅凭版本号并不容易区分。这种情况下可以考虑将commit id、build time等信息和version一起放到二进制文件中。
下面是一个示例,在程序的main包中定义了version、commitID、buildTime,
package main
import (
"flag"
"fmt"
)
var (
version string
commitID string
buildTime string
)
func printVerbose() {
fmt.Printf("version: %s\n", version)
fmt.Printf("commit_id: %s\n", commitID)
fmt.Printf("build_time: %s\n", buildTime)
}
func main() {
v := flag.Bool("version", false, "print version")
flag.Parse()
if *v {
printVerbose()
return
}
// ....
}
编译的命令写在Makefile中,在需要编译的时候只需要make一下即可。
VERSION := dev
DATE := $(shell date -u '+%Y-%m-%d-%H%M UTC')
COMMITID := $(shell git rev-parse --short HEAD)
VERSION_FLAGS := -X "main.version=$(VERSION)" -X "main.buildTime=$(DATE)" -X "main.commitID=$(COMMITID)"
all:
go build -buildvcs=false -ldflags='$(VERSION_FLAGS)' -o demo
.PHONY: clean
clean:
rm demo
常识💁♂️
值传递和引用传递
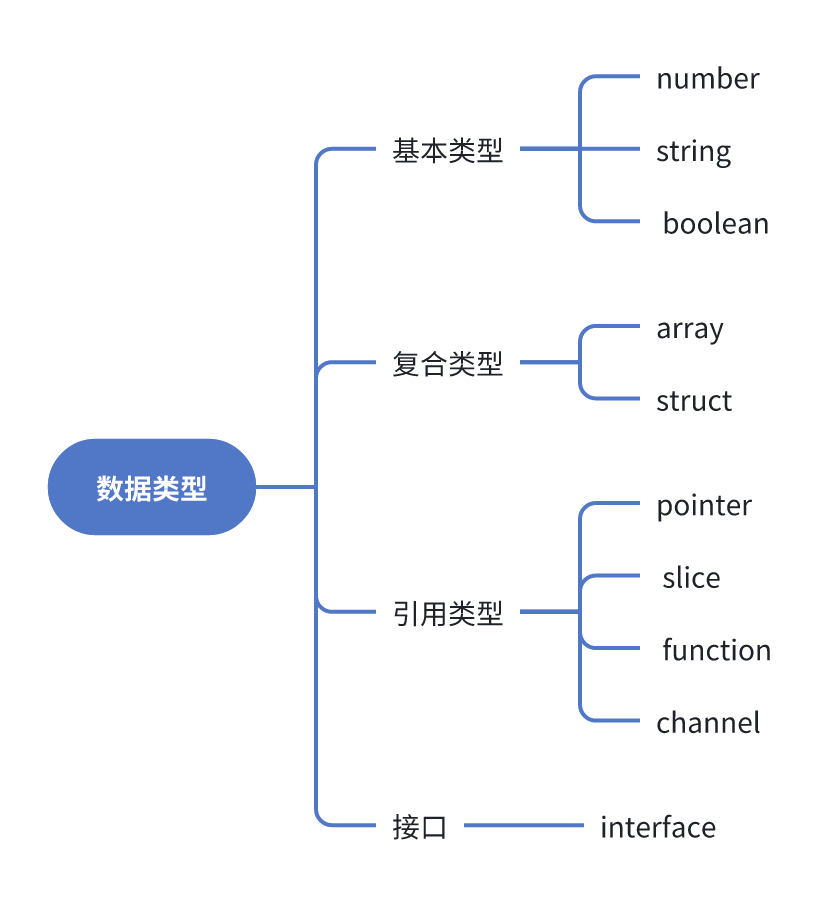
Go的data可以分为四个类型:基本类型、符合类型、引用类型和接口。常识告诉我们,在大部分情况下,通过指针传递参数的效率是最高的,但是对于string、slice、map、function而言,没有必要使用指针传递。传递struct和array可以优先考虑使用指针。
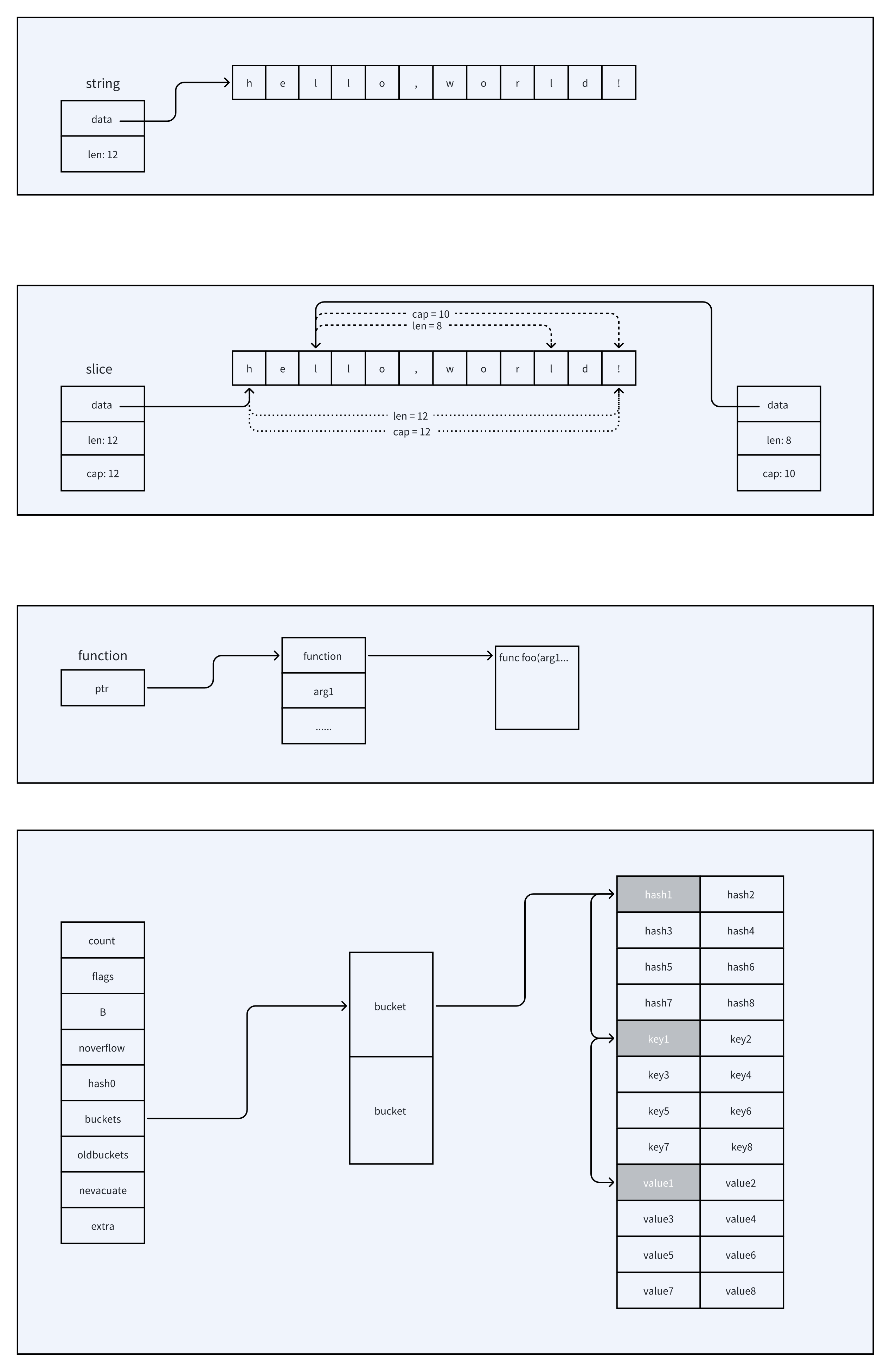
string和[]byte相互转换
string和slice可以相互转换,但是string和slice之间的转换并不是简单的指针之间的赋值,而是要将原数据复制一份到新的内存地址。
str := "hello world"
bs := []byte(str)
str2 = string(bs)
string 转 slice
string 转 slice的源码如下,如果预先分配的内存大小大于源字符串的长度,则会调用rawbyteslice申请内存,最终将源数据复制(copy)到新的内存地址。
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
// rawbyteslice allocates a new byte slice. The byte slice is not zeroed.
func rawbyteslice(size int) (b []byte) {
cap := roundupsize(uintptr(size), true)
p := mallocgc(cap, nil, false)
if cap != uintptr(size) {
memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size))
}
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)}
return
}
slice 转 string
slice转string的源码如下,可以看到要复制的string的长度超过了预先分配的内存大小n,则会调用mallocgc申请内存。无论是否需要申请新的内存,都会涉及到将源数据(string所指的内容)复制(memmove)到为slice分配的内存中。
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) string {
// ......
var p unsafe.Pointer
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false)
}
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return unsafe.String((*byte)(p), n)
}
Slice
下面的代码创建了一个能保存1000个[]byte的slice,并为每个元素申请大小为1MB的内存,然后调用keepFirstTwoElementsOnly获取前两个元素,(到Go playground运行)。
package main
import (
"fmt"
"runtime"
)
type Foo struct {
v []byte
}
func printAlloc() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("Alloc = %v KB\n", m.Alloc/1024)
}
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
return foos[:2]
}
func main() {
foos := make([]Foo, 1000)
printAlloc()
for i := 0; i < 1000; i++ {
foos[i] = Foo{
v: make([]byte, 1024*1024),
}
}
printAlloc()
two := keepFirstTwoElementsOnly(foos)
runtime.GC()
printAlloc()
runtime.KeepAlive(two)
}
解决方法
重新创建len和cap均为2的slice,把前两个元素拷贝到新的slice中,(到Go Playground运行)。
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
res := make([]Foo, 2)
copy(res, foos)
return res
}
Map
下面的代码创建了一个key为int,value为[128]的map,size为10241024的map,然后给[0~10241024)内的每个key创建一个value,然后删除所有的元素。(此代码申请的内存较多,Go Playground无法正常执行完😅,如想查看结果,需在本地执行)。
package main
import (
"fmt"
"runtime"
)
func printAlloc() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("Alloc = %v KB\n", m.Alloc/1024)
}
func main() {
n := 1024 * 1024
// create a map
m := make(map[int][128]byte)
// print the memory usage before filling the map
printAlloc()
// fill the map with 1024 * 1024 elements
for i := 0; i < n; i++ {
m[i] = [128]byte{}
}
// print the memory usage after filling the map
printAlloc()
for i := 0; i < n; i++ {
delete(m, i)
}
// force GC to clear the map
runtime.GC()
// print the memory usage after deleting the map
printAlloc()
// keep the program running
runtime.KeepAlive(m)
}
运行结果:
Alloc = 127 KB
Alloc = 464373 KB
Alloc = 300477 KB
如果将map的value类型修改为指针类型,需要的内存会少很多:
// ....
func main() {
n := 1024 * 1024
// create a map
// m := make(map[int][128]byte)
m := make(map[int]*[128]byte)
// ......
// fill the map with 1024 * 1024 elements
for i := 0; i < n; i++ {
// m[i] = [128]byte{}
m[i] = &[128]byte{}
}
// ......
}
运行结果:
Alloc = 127 KB
Alloc = 191634 KB
Alloc = 39305 KB
一个汉字占3个字节?
Go语言使用UTF-8编码,绝大部分汉字的UTF-8编码为3个字节,但是也有例外,因此不能默认所有汉字的UTF-8编码都是3个字节。下面这个例子就能说明问题(到Go Playround运行),世和界的大小都为3字节,而𠜎(xiàn)的大小为4字节。
package main
func main() {
str := "世"
println(len(str))
str = "界"
println(len(str))
str = "𠜎"
println(len(str))
}
PS:
UTF-8全称为Unicode Transformation Format - 8-bit,Unicode 是一种字符编码标准,用于表示文字在计算机中的字符集,它为世界上几乎所有的书写系统中的每个字符分配了一个唯一的数值标识,称为码点。可以理解为Unicode为每个符号分配了一个编号。而UTF-8是Unicode的一种具体实现方案,此外还有UTF-16和UTF-32等实现方案。和其他的编码方式相比,UTF-8是一种兼容ASCII,处理效率高的编码方式,因此在计算机系统和网络环境中得到了广泛的应用。(延伸:ASCII,Unicode 和 UTF-8)。
摆脱不了的内存对齐
下面S1和S2两个struct的成员类型一样,但是顺序不一样。这会导致两个结构体占用的内存大小差一倍。如果在对资源比较敏感的场景下(如制定协议字段、存储),需要考虑内存对齐。(到Go Playground运行)。
// 32 bytes
type S1 struct {
a int8
b int64
c int8
d int32
e int16
}
// 16 bytes
type S2 struct {
a int8
c int8
e int16
d int32
b int64
}
善用库
丰富的库资源是Go语言的一大优点,很多事情可以使用标准库或者优秀的第三方库来实现完成,没有必要自己重新造轮子。
使用库中的常量、变量
使用库中的常量、变量可以提高代码的可阅读性,如:
| 不使用库 | 使用库 |
|---|---|
| 200 | http.StatusOK |
| “2006-01-02 15:04:05” | time.DateTime |
使用标准库函数
在进行文件路径操作(如拼接路径,获取目录,获取文件名等)、网络地址操作(拼接IP+Port,拆分IP、Port,判断IP是否为IPv4等)可以调用标准库,即安全又高效。
推荐的第三方库
下面列举一些我自己经常用到的一些准标准库和第三方库:
| 库名 | 功能 | 应用场景 |
|---|---|---|
| logrus | 格式化日志库(具有日志等级,支持并发记录日志,支持Hook等) | 记录日志 |
| singlefly | 用于在并发环境中执行幂等函数。 | 并发查询数据库、DNS解析 |
| tableflip | 让进程优雅地重启。 | 网络程序平滑升级 |
| ttlcache | 带有过期时间的内存缓存。 | DNS缓存 |
| errorgroup | 用于在并发环境中处理错误。它可以将多个并发任务的结果聚合成一个结果,并返回第一个遇到的错误。 | 并发执行多个相互有关联的任务的场景 |
参考
- 100 Go Mistakes and How to Avoid Them (website)