XDP挂载模式对比
了解XDP的读者应该知道:XDP是基于eBPF的一个高性能网络路径技术,它的原理就是在数据包处理的早期阶段(在内核网络协议栈之前)挂载eBPF程序对数据包进行处理,从而实现高效的网络数据包处理。如果你写过XDP程序,那么一定知道挂载XDP的时候有多种模式可选,不同模式之间的效率不同。这篇文章我们就来深入剖析一下XDP的集中模式之间到底有哪些区别。
首先看看XDP挂载模式有哪几种?不同的挂载模式有和区别?
XDP挂载模式可以以三种方式挂在到网卡上:
| Generic | Native | Offloaded | |
|---|---|---|---|
| 兼容性 | 兼容所有网络设备 | 需要网卡驱动显示支持XDP | 特定的可编程网卡 |
| 执行阶段 | 在网络核心代码中执行(此时已经分配了SKB) | 在网卡驱动中执行(还未分配SKB) | 网卡执行,CPU零开销 |
| 性能 | 较低 | 高 | 最高 |
XDP 挂载原理
XDP程序是挂载在网络数据包的处理路径上的,所以我们有必要先对网络数据包的处理路径有一个整体的掌握(这里插播一条小广告,我之前写过一篇分析数据包从网卡到内核协议栈的博客)。
数据包从网卡到内核网络协议栈的流程可以分为以下几个步骤:
- 数据包到达网卡 网卡硬件接收以太帧,做基本校验(如 CRC)。
- DMA 写入内存 网卡通过 DMA 将数据包写入驱动预先分配好的接收缓冲区(Descriptor Ring)。
- 中断通知 CPU 网卡通过 IRQ 告诉 CPU:“我收到了新数据包”。
- 驱动中断处理函数(ISR) 驱动快速处理中断,通常只是调用
__napi_schedule(),把 NAPI poll 加入调度队列。 - 软中断调度 NAPI poll CPU 执行
do_softirq()→net_rx_action()→ 调用 网卡的的 poll 函数。 - poll 函数提取数据包并构造 skb 驱动在 poll 中读取 DMA ring 的描述符,把数据包封装进
sk_buff结构,交给网络核心层。 - 网络核心层处理 网络核心层根据数据包格式选择对应的协议栈,然后交给协议栈处理。
XDP就是挂载在上面的某个阶段,从而实现高效网络数据包处理的。具体来说Native模式的XDP是在网卡的驱动程序中执行的(对应步骤6),而Generic模式的XDP是在网络核心层中执行的(对应步骤7)。这也说明了Native模式的性能比Generic模式高。
下面我们就以Intel的igb网卡为例,结合Linux内核(v5.10.244)源码分析igb网卡的Native模式和Generic模式的区别。
XDP Native Model
现代的Linux内核使用了NAPI技术,将网络数据包的处理分为了上半部和下半部。上半部只处理最紧急的事情,而具体的处理则交给下半部处理。为了提高效率,NAPI采用poll(轮询)的方式处理数据包,而每个网卡都要注册自己的poll函数,igb网卡的poll函数就是igb_poll(),在igb_poll()会调用igb_clean_rx_irq()处理网卡收到的数据包。
/**
* igb_poll - NAPI Rx polling callback
* @napi: napi polling structure
* @budget: count of how many packets we should handle
**/
static int igb_poll(struct napi_struct *napi, int budget)
{
struct igb_q_vector *q_vector = container_of(napi,
struct igb_q_vector,
napi);
// ......
if (q_vector->rx.ring) {
// 处理接收到的网络数据包
int cleaned = igb_clean_rx_irq(q_vector, budget);
}
// ......
return work_done;
}
追踪到igb_clean_rx_irq()中就可以看到igb_run_xdp(),即调用Native模式的XDP程序,而且调用igb_run_xdp()的时候skb还没有分配,如果XDP程序的执行结果是XDP_DROP,则会直接丢弃数据包,省去了分配skb的消耗。但如果执行结果是XDP_PASS,就会继续执行后续的处理动作,最终igb的驱动会调napi_gro_receive()处理skb。
static int igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget)
{
struct igb_adapter *adapter = q_vector->adapter;
struct igb_ring *rx_ring = q_vector->rx.ring;
struct sk_buff *skb = rx_ring->skb;
unsigned int total_bytes = 0, total_packets = 0;
u16 cleaned_count = igb_desc_unused(rx_ring);
unsigned int xdp_xmit = 0;
struct xdp_buff xdp;
int rx_buf_pgcnt;
xdp.rxq = &rx_ring->xdp_rxq;
while (likely(total_packets < budget)) {
union e1000_adv_rx_desc *rx_desc;
struct igb_rx_buffer *rx_buffer;
unsigned int size;
// ......
rx_buffer = igb_get_rx_buffer(rx_ring, size, &rx_buf_pgcnt);
/* retrieve a buffer from the ring */
if (!skb) { // 没有分配skb,将xdp结构体的成员赋值,为调用XDP做准备
xdp.data = page_address(rx_buffer->page) +
rx_buffer->page_offset;
xdp.data_meta = xdp.data;
xdp.data_hard_start = xdp.data -
igb_rx_offset(rx_ring);
xdp.data_end = xdp.data + size;
// !!! 这里执行了XDP程序
skb = igb_run_xdp(adapter, rx_ring, &xdp);
}
// skb交给napi_gro_receive处理, Generic XDP就是在这里被执行的
napi_gro_receive(&q_vector->napi, skb);
/* reset skb pointer */
skb = NULL;
}
}
igb_run_xdp()的逻辑比较简单,就是判断是否挂载了XDP程序,如果挂载了,就执行挂载的XDP程序,然后对返回的动作处理。
static struct sk_buff *igb_run_xdp(struct igb_adapter *adapter,
struct igb_ring *rx_ring,
struct xdp_buff *xdp)
{
int err, result = IGB_XDP_PASS;
struct bpf_prog *xdp_prog;
u32 act;
rcu_read_lock();
xdp_prog = READ_ONCE(rx_ring->xdp_prog);
if (!xdp_prog) // 如果没有挂载XDP,直接返回
goto xdp_out;
prefetchw(xdp->data_hard_start); /* xdp_frame write */
// 执行XDP程序,根据执行结果设置返回值
act = bpf_prog_run_xdp(xdp_prog, xdp);
switch (act) {
case XDP_PASS:
break;
case XDP_TX:
result = igb_xdp_xmit_back(adapter, xdp);
if (result == IGB_XDP_CONSUMED)
goto out_failure;
break;
case XDP_REDIRECT:
err = xdp_do_redirect(adapter->netdev, xdp, xdp_prog);
if (err)
goto out_failure;
result = IGB_XDP_REDIR;
break;
default:
bpf_warn_invalid_xdp_action(act);
fallthrough;
case XDP_ABORTED:
out_failure:
trace_xdp_exception(rx_ring->netdev, xdp_prog, act);
fallthrough;
case XDP_DROP:
result = IGB_XDP_CONSUMED;
break;
}
xdp_out:
rcu_read_unlock();
return ERR_PTR(-result);
}
通过分析源码,我们知道了Native模式高效的原因就是它的在数据包处理的早期阶段执行,这个时候还没有为数据包分配skb。
XDP Generic Model
napi_gro_receive() 会调用napi_skb_finish()处理skb。
上面在分析igb的poll函数时,我们看到了igb_poll()会调用igb_clean_rx_irq()处理数据包,igb_rx_irq()最终会将skb交给napi_gro_receive(),下面是napi_gro_receive()的实现,它会调用其他函数,最终会调用到do_xdp_generic()函数执行以Generic模式挂载的XDP程序。
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
gro_result_t ret;
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb, 0);
// 处理skb
ret = napi_skb_finish(napi, skb, dev_gro_receive(napi, skb));
trace_napi_gro_receive_exit(ret);
return ret;
}
EXPORT_SYMBOL(napi_gro_receive);
从napi_gro_receive()到do_xdp_generic()的调用链非常长,所以下面就以一个图片来展示这个调用链。
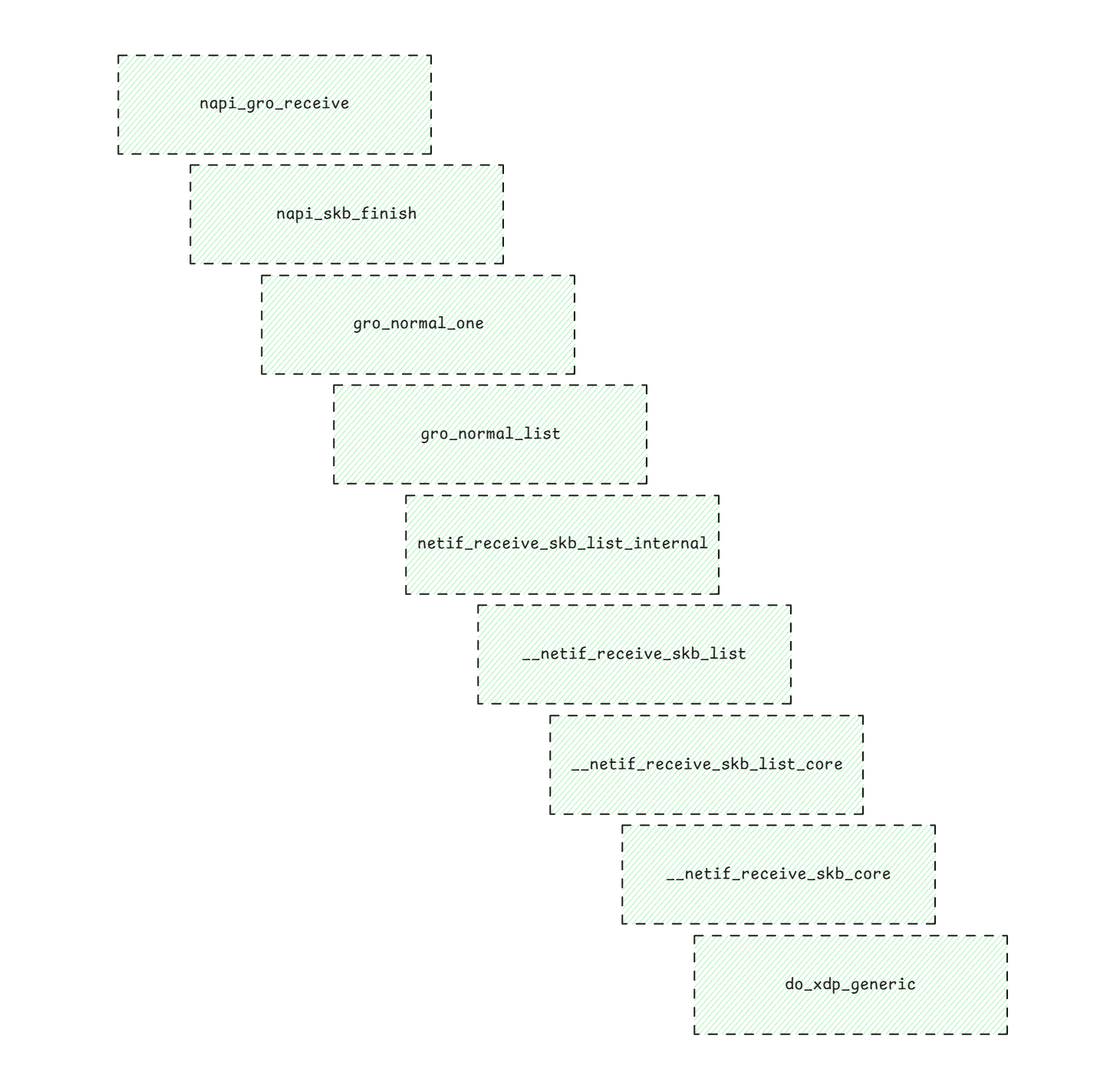
通过上面的调用链可以看到do_xdp_generic()是被__netif_receive_skb_core()调用的。__netif_receive_skb_core()干了很多事情,包括:
- 执行Generic
XDP程序; - 执行tcpdump抓包指令;
- 执行挂载在tc ingress上的程序;
- 执行挂载在netfilter ingress上的程序;
- 分发给对应的网络协议栈;
从这个函数可以清晰的看到XDP、tcpdump、tc ingress、netfilter和网络协议栈的顺序关系。
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev)
{
if (static_branch_unlikely(&generic_xdp_needed_key)) {
// Generic model XDP program执行点!!!
ret2 = do_xdp_generic(rcu_dereference(skb->dev->xdp_prog), skb);
if (ret2 != XDP_PASS) {
ret = NET_RX_DROP;
goto out;
}
}
// tcpdump抓包的地方
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
#ifdef CONFIG_NET_INGRESS
if (static_branch_unlikely(&ingress_needed_key)) {
bool another = false;
// tc ingress执行点
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev,
&another);
if (another)
goto another_round;
if (!skb)
goto out;
// netfilter ingress执行点
if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0)
goto out;
}
#endif
// ......
type = skb->protocol;
/* deliver only exact match when indicated */
// IP数据包在此被分发到内核协议栈处理
if (likely(!deliver_exact)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&ptype_base[ntohs(type) &
PTYPE_HASH_MASK]);
}
// ......
}
总结
这篇文章结合Linux源码分析了XDP的Native和Generic模式两种模式的区别:Native模式是在网卡的驱动中执行的,执行的时候还未分配skb,这也要求必须网卡驱动支持XDP才能以Native模式挂载。Generic模式是在网络核心层执行的,此时已经分配了skb,虽然性能不如Native模式,但是仍然在tcpdump和协议栈之前。