引言
网络数据包从网卡到应用程序,需要经历一段复杂的旅程。作为开发者,我们平时调用 socket()、recv() 就能轻松拿到数据,却很少思考内核背后究竟发生了什么。
本系列文章尝试结合 理论流程 + 内核源码分析,逐步剖析 Linux 内核中网络数据包的接收过程。这里选择 Linux 4.4 内核作为例子(代码相对稳定,资料丰富,逻辑上没有过多新特性干扰),并结合 Intel e1000 驱动来具体展示数据包是如何从网卡到达内核网络协议栈的。
网络数据包接收的总体流程
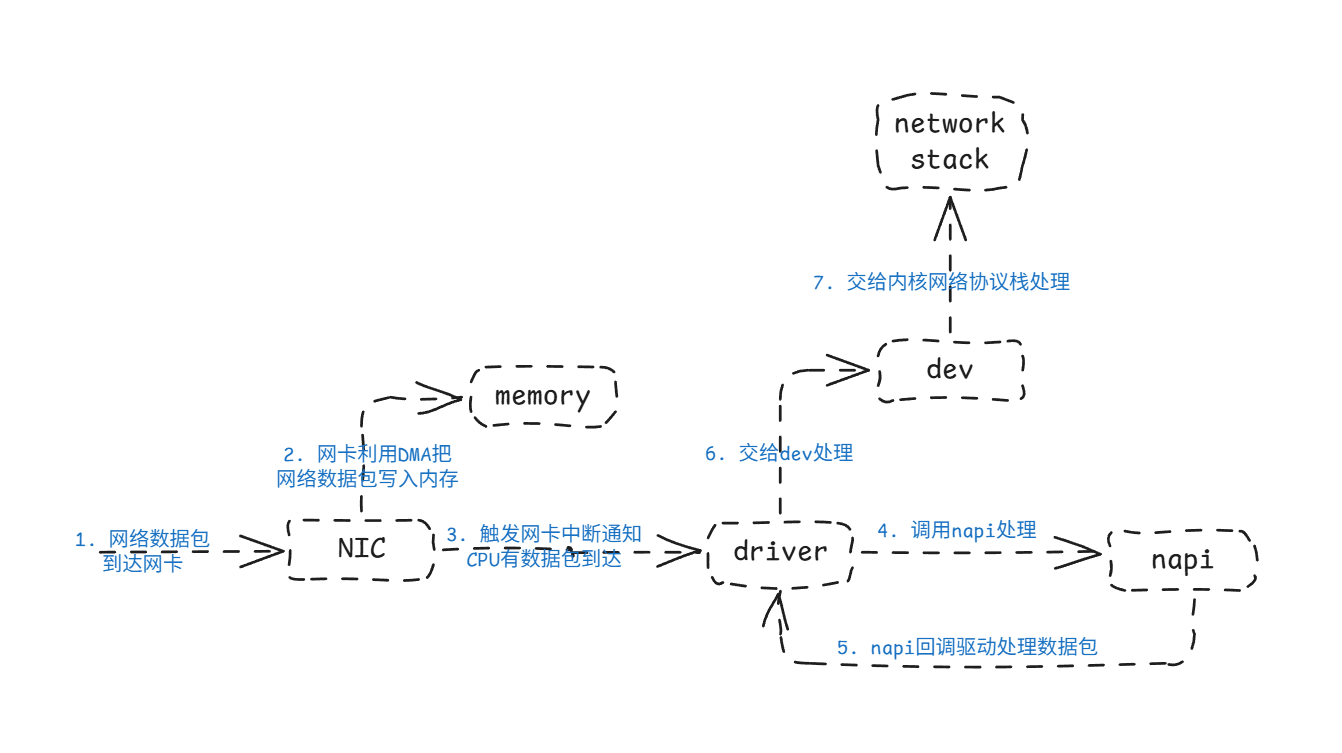
先给出一个全局视角:数据包从网卡到达内存,再到协议栈的路径,大致如下:
- 数据包到达网卡 网卡硬件接收以太帧,做基本校验(如 CRC)。
- DMA 写入内存 网卡通过 DMA 将数据包写入驱动预先分配好的接收缓冲区(Descriptor Ring)。
- 中断通知 CPU 网卡通过 IRQ 告诉 CPU:“我收到了新数据包”。
- 驱动中断处理函数(ISR)
驱动快速处理中断,通常只是调用
__napi_schedule(),把 NAPI poll 加入调度队列。 - 软中断调度 NAPI poll
CPU 执行
do_softirq()→net_rx_action()→ 调用 e1000 的 poll 函数。 - poll 函数提取数据包并构造 skb
驱动在 poll 中读取 DMA ring 的描述符,把数据包封装进
sk_buff结构,交给内核网络子系统。 - 网络核心层处理 skb 被送到网络核心层,核心层通过数据包的协议类型选择对应的网络协议栈,如IP协议栈,至此网络数据包从网卡到达了Linux内核的网络协议栈。
在开始具体分析之前,先说以下相关源码的位置。和网卡相关的代码在驱动目录下(/drivers/net/ethernet),由于我们分析的是Intel的e1000网卡,所以具体位置就是/drivers/net/ethernet/intel/e1000,内核网络协议栈位于网络子系统目录下/net,主要是/net/core/目录,我们主要分析IPv4,所以还会涉及/net/ipv4/中的少量代码。
接下来就以Intel e1000网卡为例,来一起探究网卡收包过程吧😀
e1000 网卡 DMA 收包机制
e1000 网卡使用了 DMA(Direct Memory Access):网卡硬件自己把数据写入内存中的接收缓冲区。那么Linux内核就要告诉网卡在DMA操作的时候把网络数据包copy到内存的哪个位置?这就需要网卡的驱动提前为网卡分配好专门保存数据包的内存,也就是ring buffer。
Ring Buffer 与描述符队列
驱动在初始化时,会为接收数据分配一块环形队列(Rx Ring Buffer)。
- 队列中包含多个 接收描述符(Rx Descriptor)。
- 每个描述符里有:
- Buffer 地址(物理地址,告诉网卡数据该写到哪)
- Status 标志位(如 DD=1 表示数据已经写好)
网卡在收包时,就会:
- 读取下一个描述符里的缓冲区地址
- 把数据包通过 DMA 写入这块内存
- 设置描述符状态(DD=1)
- 移动到下一个描述符
这样 CPU 完全不用参与搬运,只需在合适的时机读取描述符即可。
源码片段:Rx Ring Buffer 初始化
以 Linux 4.4 内核的 e1000 驱动为例,接收队列初始化逻辑在 e1000_setup_rx_resources() 中(位于 drivers/net/ethernet/intel/e1000/e1000_main.c)。这段代码展示了给管理缓冲区的e1000_rx_ring结构体的成员赋值情况。
// file: drivers/net/ethernet/intel/e1000/e1000_main.c
/**
* e1000_setup_rx_resources - allocate Rx resources (Descriptors)
* @adapter: board private structure
* @rxdr: rx descriptor ring (for a specific queue) to setup
*
* Returns 0 on success, negative on failure
**/
static int e1000_setup_rx_resources(struct e1000_adapter *adapter,
struct e1000_rx_ring *rxdr)
{
struct pci_dev *pdev = adapter->pdev;
int size, desc_len;
size = sizeof(struct e1000_rx_buffer) * rxdr->count;
rxdr->buffer_info = vzalloc(size); // 为buffer_info分配空间,buffer_info是一个数组,每个元素描述一个接收buffer
if (!rxdr->buffer_info)
return -ENOMEM;
desc_len = sizeof(struct e1000_rx_desc);
/* Round up to nearest 4K */
rxdr->size = rxdr->count * desc_len;
rxdr->size = ALIGN(rxdr->size, 4096);
rxdr->desc = dma_alloc_coherent(&pdev->dev, rxdr->size, &rxdr->dma,
GFP_KERNEL); // 分配一块连续的物理内存用于存放描述符数组
if (!rxdr->desc) {
setup_rx_desc_die:
vfree(rxdr->buffer_info);
return -ENOMEM;
}
// ...
memset(rxdr->desc, 0, rxdr->size); // 把所有文件描述符换清空
rxdr->next_to_clean = 0; // 下一个驱动要收回的描述符索引
rxdr->next_to_use = 0; // 下一个硬件可以用来DMA的描述符索引
rxdr->rx_skb_top = NULL; // 用于大包接收时(分段skb)的临时缓存
return 0;
}
看完这个函数不知道你是否有这样一个问题:这个函数申请了两块内存,一块是用来存放e1000_rx_buffer数组的,另一块是用来存放e1000_rx_desc数组的。这两个数组的元素都是用来描述真正的缓冲区的,但是这里偏偏没有分配缓冲区的操作。相反,还给e1000_rx_desc的所有元素都初始化为0了。其实申请缓冲区的操作在同一个文件的另一个函数e1000_alloc_rx_buffers中,这个函数主要工作就分配指定数量的buffer,并将buffer与e1000_rx_ring结构体的buffer_info和desc成员关联起来。
// file: drivers/net/ethernet/intel/e1000/e1000_main.c
/**
* e1000_alloc_rx_buffers - Replace used receive buffers; legacy & extended
* @adapter: address of board private structure
**/
static void e1000_alloc_rx_buffers(struct e1000_adapter *adapter,
struct e1000_rx_ring *rx_ring,
int cleaned_count)
{
struct e1000_hw *hw = &adapter->hw;
struct pci_dev *pdev = adapter->pdev;
struct e1000_rx_desc *rx_desc;
struct e1000_rx_buffer *buffer_info;
unsigned int i;
unsigned int bufsz = adapter->rx_buffer_len;
i = rx_ring->next_to_use;
buffer_info = &rx_ring->buffer_info[i];
while (cleaned_count--) {
void *data;
if (buffer_info->rxbuf.data)
goto skip;
// 为buffer分配内存
data = e1000_alloc_frag(adapter);
if (!data) {
/* Better luck next round */
adapter->alloc_rx_buff_failed++;
break;
}
// ......
// 将buffer与buffer_info关联
buffer_info->dma = dma_map_single(&pdev->dev,
data,
adapter->rx_buffer_len,
DMA_FROM_DEVICE);
if (dma_mapping_error(&pdev->dev, buffer_info->dma)) {
skb_free_frag(data);
buffer_info->dma = 0;
adapter->alloc_rx_buff_failed++;
break;
}
buffer_info->rxbuf.data = data;
skip:
// 将buffer与rx_desc关联
rx_desc = E1000_RX_DESC(*rx_ring, i);
rx_desc->buffer_addr = cpu_to_le64(buffer_info->dma);
if (unlikely(++i == rx_ring->count))
i = 0;
buffer_info = &rx_ring->buffer_info[i];
}
if (likely(rx_ring->next_to_use != i)) {
rx_ring->next_to_use = i;
if (unlikely(i-- == 0))
i = (rx_ring->count - 1);
/* Force memory writes to complete before letting h/w
* know there are new descriptors to fetch. (Only
* applicable for weak-ordered memory model archs,
* such as IA-64).
*/
wmb();
writel(i, hw->hw_addr + rx_ring->rdt);
}
}
这就是网卡的接收环形缓冲区的初始化过程,初始化之后,网卡收到数据包之后就可以用DMA直接将数据包copy到对应的buffer中,并更新e1000_rx_ring的成员,然后就会触发中断,通知CPU有数据包到达。下面就该分析CPU是如何处理这个中断请求的。
CPU 如何处理 e1000 网卡中断
当网卡接收到数据包并通过 DMA 写入内存后,会向 CPU 发出中断请求(IRQ),通知有新数据到达。Linux 内核中的 e1000 驱动会在中断向量表中注册自己的中断处理函数—— e1000_intr。
中断处理函数运行在 硬中断上下文,主要完成三件事:
- 读取并清除网卡的中断状态寄存器,确认事件类型(Rx、Tx、链路变化等)。
- 临时屏蔽中断,避免重复触发。
- 调度 NAPI poll,调用
napi_schedule(&adapter->napi)将网卡加入软中断处理队列。
NAPI(New API)是 Linux 的网络中断减载机制:在高流量下,它通过轮询(poll)批量处理数据包,而不是为每个数据包触发硬中断。
// file: drivers/net/ethernet/intel/e1000/e1000_main.c
/**
* e1000_intr - Interrupt Handler
* @irq: interrupt number
* @data: pointer to a network interface device structure
**/
static irqreturn_t e1000_intr(int irq, void *data)
{
struct net_device *netdev = data;
struct e1000_adapter *adapter = netdev_priv(netdev);
struct e1000_hw *hw = &adapter->hw;
u32 icr = er32(ICR);
if (unlikely((!icr)))
return IRQ_NONE; /* Not our interrupt */
/* we might have caused the interrupt, but the above
* read cleared it, and just in case the driver is
* down there is nothing to do so return handled
*/
if (unlikely(test_bit(__E1000_DOWN, &adapter->flags)))
return IRQ_HANDLED;
if (unlikely(icr & (E1000_ICR_RXSEQ | E1000_ICR_LSC))) {
hw->get_link_status = 1;
/* guard against interrupt when we're going down */
if (!test_bit(__E1000_DOWN, &adapter->flags))
schedule_delayed_work(&adapter->watchdog_task, 1);
}
/* disable interrupts, without the synchronize_irq bit */
ew32(IMC, ~0); // 禁止IMC(Interrupt Mask Clear)中断
E1000_WRITE_FLUSH();
if (likely(napi_schedule_prep(&adapter->napi))) {
adapter->total_tx_bytes = 0;
adapter->total_tx_packets = 0;
adapter->total_rx_bytes = 0;
adapter->total_rx_packets = 0;
__napi_schedule(&adapter->napi); // 调度napi
} else {
/* this really should not happen! if it does it is basically a
* bug, but not a hard error, so enable ints and continue
*/
if (!test_bit(__E1000_DOWN, &adapter->flags))
e1000_irq_enable(adapter);
}
return IRQ_HANDLED;
}
e1000_intr做的事情是不是很少?这就对了,因为Linux内核处理硬件中断使用了上半部/下半部的两阶段机制,核心目的是既要尽快响应硬件,又要避免长时间占用CPU。上半部只做紧急的工作,如确认中断来源、通知硬件已收到通知、唤醒下半部等。e1000_intr就属于中断的上半部。
软中断与 NAPI 轮询机制
在上一节中,我们看到网卡触发硬中断后,e1000 驱动的中断处理函数(e1000_intr)主要完成了 确认事件 → 临时屏蔽中断 → 调度 NAPI。那么接下来,真正的收包工作是如何展开的呢?这就涉及到 Linux 网络子系统里的 软中断 和 NAPI。
硬中断到软中断的过渡
e1000_intr调用了__napi_schedule来调度NAPI。napi_schedule还会调用____napi_schedule。__napi_schedule()的操作就是:
- 把当前网卡对应的
napi_struct对象加入到全局的 NAPI 队列; - 设置
NET_RX_SOFTIRQ标志,告诉内核后续需要执行网络接收的软中断。
这样,真正的数据包处理就被延迟到了软中断上下文执行,避免在硬中断上下文里做大量工作。
// file: net/core/dev.c
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list); // 把napi_struct对象加入到全局的NAPI队列
__raise_softirq_irqoff(NET_RX_SOFTIRQ); // 设置NET_RX_SOFTIRQ标志,告诉内核后续要执行网络接收的软中断
}
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
____napi_schedule(this_cpu_ptr(&softnet_data), n); // 调用____napi_schedule
local_irq_restore(flags);
}
EXPORT_SYMBOL(__napi_schedule);
软中断由 do_softirq() 执行,其中会调用 net_rx_action(),这是因为net_dev在初始化的时候会注册NET_RX_SOFTIRQ和NET_TX_SOFTIRQ软中断。
// file: net/core/dev.c
/*
* Initialize the DEV module. At boot time this walks the device list and
* unhooks any devices that fail to initialise (normally hardware not
* present) and leaves us with a valid list of present and active devices.
*
*/
/*
* This is called single threaded during boot, so no need
* to take the rtnl semaphore.
*/
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
// ......
open_softirq(NET_TX_SOFTIRQ, net_tx_action); // 指定由 net_tx_action 处理 NET_TX_SOFTIRQ 软中断
open_softirq(NET_RX_SOFTIRQ, net_rx_action); // 指定由 net_rx_action 处理 NET_RX_SOFTIRQ 软中断
// ......
return rc;
}
subsys_initcall(net_dev_init);
net_rx_action() 的职责是轮询 NAPI 队列,逐个调用设备驱动注册的 poll 方法。 对 e1000 驱动来说,这个 poll 函数就是 e1000_clean()。
// file: net/core/dev.c
static void net_rx_action(struct softirq_action *h)
{
// ......
for (;;) {
struct napi_struct *n;
// ......
n = list_first_entry(&list, struct napi_struct, poll_list); // 从napi struct队列中取出napi对象
budget -= napi_poll(n, &repoll); // 将对象交给 napi_poll 处理,对于e1000驱动来说,poll就是e1000_clean
// ......
}
// ......
}
static int napi_poll(struct napi_struct *n, struct list_head *repoll)
{
void *have;
int work, weight;
// ......
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight); // 调用 napi struct 对象的 poll 函数处理
trace_napi_poll(n);
}
// ......
return work;
}
最终软中断还是调用了e1000网卡的驱动函数e1000_clean。e1000_clean的职责是:在软中断上下文中处理收包与发包的完成逻辑。这里我们只关注收包,忽略发包。发包的逻辑实际是调用adapter->clean_rx来完成的。
// file: drivers/net/ethernet/intel/e1000/e1000_main.c
/**
* e1000_clean - NAPI Rx polling callback
* @adapter: board private structure
**/
static int e1000_clean(struct napi_struct *napi, int budget)
{
struct e1000_adapter *adapter = container_of(napi, struct e1000_adapter,
napi);
int tx_clean_complete = 0, work_done = 0;
/* 1. 回收发送队列 */
tx_clean_complete = e1000_clean_tx_irq(adapter, &adapter->tx_ring[0]);
/* 2. 处理接收队列 */
adapter->clean_rx(adapter, &adapter->rx_ring[0], &work_done, budget);
/* 3. 如果发送队列没清理干净,强制认为收包已经达到 budget */
if (!tx_clean_complete)
work_done = budget;
/* 4. 如果收发工作没用完 budget,说明任务完成,可以退出 NAPI 轮询 */
/* If budget not fully consumed, exit the polling mode */
if (work_done < budget) {
if (likely(adapter->itr_setting & 3))
e1000_set_itr(adapter); // 动态调整中断频率
napi_complete_done(napi, work_done); // 标记 NAPI 处理完成
if (!test_bit(__E1000_DOWN, &adapter->flags))
e1000_irq_enable(adapter); // 重新开启中断
}
return work_done;
}
为什么发包直接调用e1000_clean_tx_irq,而收报不是直接调用e1000_clean_rx_irq呢?这是因为处理收包的函数有多个,具体使用哪个是由配置决定的。具体来说就是,如果MTU大于标准以太网数据长度ETH_DATA_LEN(1500 字节)就使用专门处理巨帧的函数,否则就使用普通的收包函数。后面我们以普通收包函数(e1000_clean_rx_irq)为例进行分析。
// file: drivers/net/ethernet/intel/e1000/e1000_main.c
static void e1000_configure_rx(struct e1000_adapter *adapter)
{
// ......
if (adapter->netdev->mtu > ETH_DATA_LEN) { // 检查 mtu 是否大于 ETH_DATA_LEN(1500)
rdlen = adapter->rx_ring[0].count *
sizeof(struct e1000_rx_desc);
adapter->clean_rx = e1000_clean_jumbo_rx_irq; // 使用专门处理jumbo frame的收包函数
adapter->alloc_rx_buf = e1000_alloc_jumbo_rx_buffers;
} else {
rdlen = adapter->rx_ring[0].count *
sizeof(struct e1000_rx_desc);
adapter->clean_rx = e1000_clean_rx_irq; // 使用普通收包函数
adapter->alloc_rx_buf = e1000_alloc_rx_buffers;
}
// ......
}
概括来说e1000_clean_rx_irq从DMA ring取出报文,封装成skb,然后交给e1000_receive_skb处理。具体包括:
检查 DMA 完成标志
- 每个
rx_desc(接收描述符)在网卡写完数据后,会设置E1000_RXD_STAT_DD。 - 驱动只处理已经 DMA 完成的 buffer。
构造 skb
- 小包:调用
e1000_copybreak(),复制数据到新建的skb。 - 大包:直接用
build_skb(),避免复制开销,直接复用 DMA buffer。
丢弃非法数据包
- 如果包跨越多个 buffer(
EOP未置位),直接丢弃。 - 硬件发现的错误帧(CRC 错误等)也会丢弃。
合法数据包处理
- 调整
skb长度,去掉以太网 CRC。 - 调用
e1000_rx_checksum()做硬件校验和 offload。 - 调用
e1000_receive_skb()把报文交给 Linux 网络协议栈(从这一刻开始,数据包就进入了 TCP/IP 栈)。
回收和补充 buffer
- 清空
rx_desc->status,表示这个描述符可以再次被网卡使用。 - 定期调用
alloc_rx_buf()给网卡补充新的空 buffer,避免 ring buffer 被耗尽。
// file: drivers/net/ethernet/intel/e1000/e1000_main.c
/**
* e1000_clean_rx_irq - Send received data up the network stack; legacy
* @adapter: board private structure
* @rx_ring: ring to clean
* @work_done: amount of napi work completed this call
* @work_to_do: max amount of work allowed for this call to do
*/
static bool e1000_clean_rx_irq(struct e1000_adapter *adapter,
struct e1000_rx_ring *rx_ring,
int *work_done, int work_to_do)
{
struct net_device *netdev = adapter->netdev;
struct pci_dev *pdev = adapter->pdev;
struct e1000_rx_desc *rx_desc, *next_rxd;
struct e1000_rx_buffer *buffer_info, *next_buffer;
u32 length;
unsigned int i;
int cleaned_count = 0;
bool cleaned = false;
unsigned int total_rx_bytes=0, total_rx_packets=0;
i = rx_ring->next_to_clean;
rx_desc = E1000_RX_DESC(*rx_ring, i);
buffer_info = &rx_ring->buffer_info[i];
while (rx_desc->status & E1000_RXD_STAT_DD) { // 检查DMA是否完成,DD = Descriptor Done
struct sk_buff *skb;
u8 *data;
u8 status;
if (*work_done >= work_to_do)
break;
(*work_done)++;
dma_rmb(); /* read descriptor and rx_buffer_info after status DD */
status = rx_desc->status;
length = le16_to_cpu(rx_desc->length);
data = buffer_info->rxbuf.data; // data就是真正的buffer
prefetch(data);
// 构造skb,如果是小包,直接把数据包内从从buffer中copy一份,否则直接使用buffer
skb = e1000_copybreak(adapter, buffer_info, length, data); // 为小包分配skb,如果是大包,返回NULL
if (!skb) { // 处理大包
unsigned int frag_len = e1000_frag_len(adapter);
skb = build_skb(data - E1000_HEADROOM, frag_len); // 为大包构造skb
// ......
}
// ......
process_skb:
total_rx_bytes += (length - 4); /* don't count FCS */
total_rx_packets++;
if (likely(!(netdev->features & NETIF_F_RXFCS)))
/* adjust length to remove Ethernet CRC, this must be
* done after the TBI_ACCEPT workaround above
*/
length -= 4;
// 调整skb
if (buffer_info->rxbuf.data == NULL)
skb_put(skb, length);
else /* copybreak skb */
skb_trim(skb, length);
//
/* Receive Checksum Offload */
e1000_rx_checksum(adapter,
(u32)(status) |
((u32)(rx_desc->errors) << 24),
le16_to_cpu(rx_desc->csum), skb);
// 交给e1000_receive_skb处理
e1000_receive_skb(adapter, status, rx_desc->special, skb);
// ......
}
// ......
// 更新统计信息
adapter->total_rx_packets += total_rx_packets;
adapter->total_rx_bytes += total_rx_bytes;
netdev->stats.rx_bytes += total_rx_bytes;
netdev->stats.rx_packets += total_rx_packets;
return cleaned;
}
e1000_receive_skb根据协议(对于e1000网卡来说,就是以太网协议)调整skb的相关字段(如mac_header、data等),然后将skb交给napi_gro_receive处理。
// file: drivers/net/ethernet/intel/e1000/e1000_main.c
/**
* e1000_receive_skb - helper function to handle rx indications
* @adapter: board private structure
* @status: descriptor status field as written by hardware
* @vlan: descriptor vlan field as written by hardware (no le/be conversion)
* @skb: pointer to sk_buff to be indicated to stack
*/
static void e1000_receive_skb(struct e1000_adapter *adapter, u8 status,
__le16 vlan, struct sk_buff *skb)
{
skb->protocol = eth_type_trans(skb, adapter->netdev); // 调整skb的mac_header,根据L2 header判断协议类型,并将skb->data指向下一层协议头
if (status & E1000_RXD_STAT_VP) {
u16 vid = le16_to_cpu(vlan) & E1000_RXD_SPC_VLAN_MASK;
__vlan_hwaccel_put_tag(skb, htons(ETH_P_8021Q), vid);
}
napi_gro_receive(&adapter->napi, skb); // 交给上层协议栈处理
}
napi_gro_receive是Linux内核GRO(Generic Receive Offload)接收路径的一个函数,实现了对接收到的skb进行聚合处理。这里我们不关心具体的聚合操作细节(只需要知道dev_gro_receive会给napi_skb_finish返回聚合的结果即可),直接看napi_skb_finish是如何处理skb的。napi_skb_finish根据聚合结果判断是否继续处理skb,正常情况下会将skb交给其他函数处理,最终skb会被__netif_receive_skb_core处理。
// file: net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
trace_napi_gro_receive_entry(skb); // 追踪调试入口,可用于ftrace等跟踪工具
skb_gro_reset_offset(skb); // 重置 skb 的 GRO 状态,让 skb 可以参与聚合
// 调用 dev_gro_receive 将 skb 交给设备层的 GRO,
// dev_gro_receive 会尝试将多个小包聚合成大包,提高处理效率
// napi_skb_finish 根据 dev_gro_receive 的返回结果做后续处理
return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}
EXPORT_SYMBOL(napi_gro_receive);
__netif_receive_skb_core比较长,以下是保留了skb分发逻辑的简化版本。主要流程如下:
先分发给全局链表
ptype_all(tcpdump 等监听工具会在这里收到数据包)。再分发给网卡专属链表
dev->ptype_all(网卡功能相关)。调用网卡
rx_handler(驱动自定义的接收回调)。根据协议类型分发给 IPv4/IPv6/ARP等处理。
最后调用最后一个 packet_type 的处理函数或丢弃。
对于IP数据包,就会分发给ip_rcv函数处理。至此网络数据包就从网卡到达到了网络协议栈的入口。
// file: net/core/dev.c
static int __netif_receive_skb_core(struct sk_buff *skb)
{
struct packet_type *ptype, *pt_prev;
rx_handler_func_t *rx_handler;
struct net_device *orig_dev;
int ret = NET_RX_DROP;
__be16 type;
orig_dev = skb->dev;
pt_prev = NULL;
// 1. 分发给全局 packet_type 链表(所有网卡共享)
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
// 2. 分发给当前网卡专属 packet_type 链表
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
// 3. 调用网卡驱动可能设置的 rx_handler
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
if (pt_prev) {
deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
return NET_RX_SUCCESS;
case RX_HANDLER_ANOTHER:
// skb 被重定向,需要再次分发
pt_prev = NULL;
break;
case RX_HANDLER_EXACT:
case RX_HANDLER_PASS:
break;
}
}
// 4. 按协议类型分发给对应链表(IPv4/IPv6/ARP)
type = skb->protocol;
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK]); // 对于TCP/UDP,就是在这里分发给IPv4处理的
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&orig_dev->ptype_specific);
// 5. 最终调用最后一个 packet_type 的处理函数,或者丢弃
if (pt_prev)
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
else {
kfree_skb(skb);
ret = NET_RX_DROP;
}
return ret;
}
这里插播一段内容:tcpdump的抓包的实现原理其实就是创建PF_PACKET类型的socket并添加到ptype_all或者dev->ptype_all,而每一个数据包都会经历前面的1、2两个分发过程。可以看到tcpdump的抓包位置在数据包处理的早期(入向流量),所以即使数据包会被丢弃,tcpdump也能抓到完整的数据包。
如何确定把数据包分发给谁处理呢?对于IPv4数据包而言,e1000网卡在将skb交给napi_gro_receive前,会设置skb->protocol,__netif_receive_skb_core在分发的时候会在ptype_base中查找匹配的处理函数,对于IPv4而言,在初始化的时候会将ip_packet_type添加到ptype_base中。
// file: net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv, // 处理IP数据包的函数
};
static int __init inet_init(void)
{
// ......
dev_add_pack(&ip_packet_type);
// ......
}
总结
经过一通分析,终于把数据包从网卡送到了内核网络协议栈,还意外的发现了tcpdump抓包的位置(入向包),真不容易。回过头来再看这个过程:
- 数据包达到网卡;
- 网卡通过DMA将数据包写入驱动预先分配好的接收缓冲区;
- 网卡通过IRQ告诉CPU有新的网络数据包到达;
- CPU快速响应网卡的IRQ请求,简单调用
__napi_schedule(),把NAPI poll加入调度队列; - 软中断调度NAPI poll,最终调用e1000网卡的poll函数(
e1000_clean); - 网卡的poll函读取DMA ring描述符,把数据包封装进sk_buff结构体(即skb),交给内核网络子系统;
- 内核网络子系统按照协议类型将skb分发给对应的处理函数,对于IP数据包而言,处理函数就是
ip_rcv;
在分析的过程中,我们还看到了在分发skb时会遍历ptype_all,如果使用tcpdump抓包,tcpdump创建的socket就会被添加到ptype_all中,所以就能抓到L2~L7的完整数据包。
ip_rcv如何处理数据包的呢?这涉及到路由以及分发给L4层处理(如TCP/UDP)。这块内容留在下一篇文章介绍。