Linux 下多语言网络编程对比
还记得Linux网络编程姿势吗?如果不记得了,这里有一个用C语言写的tcp_echo服务,用这段代码能帮我们回忆Linux的网络编程套路:
- 调用socket创建一个网络套接字socket;
- 调用bind给socket绑定地址;
- listen设置
- 调用accept接收网络请求;
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
int main(void) {
int sd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in addr = {
.sin_family = AF_INET,
.sin_port = htons(12345),
.sin_addr.s_addr = INADDR_ANY,
};
bind(sd, (struct sockaddr*)&addr, sizeof(addr));
listen(sd, 5);
while (1) {
int client = accept(sd, NULL, NULL);
char buf[1024];
ssize_t n;
while ((n = recv(client, buf, sizeof(buf), 0)) > 0) {
send(client, buf, n, 0); // 把读到的内容发送回去
}
close(client);
}
close(sd);
return 0;
}
如果你用的是Go、Python、Rust等高级编程语言,可能会对这段代码嗤之以鼻,这么简单一个功能,要创建一个可以通信的TCP连接完全不必这么复杂。
这是用Go写的,如果不考虑错误处理,只需要调用Listen和Accept。
package main
import (
"io"
"net"
)
func main() {
ln, err := net.Listen("tcp", "127.0.0.1:12345")
if err != nil {
panic("listen err")
}
for {
conn, err := ln.Accept()
if err != nil {
panic("accept error")
}
go func(conn net.Conn) {
defer conn.Close()
io.Copy(conn, conn)
}(conn)
}
}
使用Rust标准库std::net的同步版本如下。
fn main() {
let l = std::net::TcpListener::bind(("127.0.0.1", 12345)).unwrap();
for s in l.incoming() {
std::thread::spawn(move || {
let mut w = s.unwrap();
let mut r = w.try_clone().unwrap();
let _ = std::io::copy(&mut r, &mut w);
});
}
}
使用Rust标准库tokio::net的异步版本如下。
#[tokio::main]
async fn main() {
let l = tokio::net::TcpListener::bind(("127.0.0.1", 12345))
.await
.unwrap();
loop {
let (s, _) = l.accept().await.unwrap();
tokio::spawn(async move {
let (mut r, mut w) = s.into_split();
let _ = tokio::io::copy(&mut r, &mut w).await;
});
}
}
可以看到,使用不同语言进行网络编程,风格差别很大。但是实际不管是C这样古老的编程语言,还是像Go、Rust这样比较现代化的高级编程语言,他们都是对内核提供的网络编程接口进行了封装,本质上底层上是一样的。怎么证明这一结论的正确性呢?可以使用strace来追踪进程的系统调用,看看进程调用了哪些系统调用。
以下是对上面四段代码编译后使用strace工具追踪的结果:
C版追踪结果
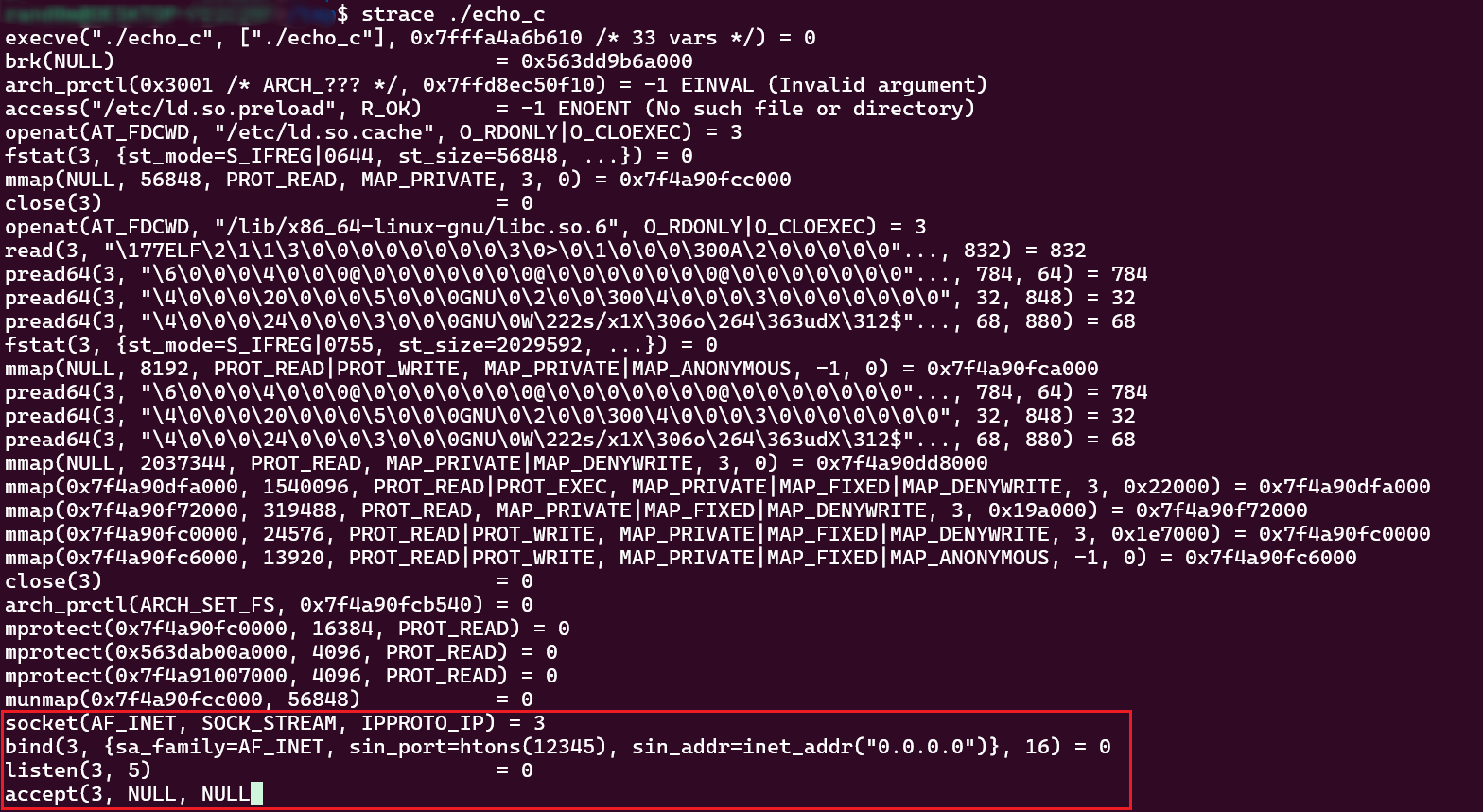
可以看到追踪结果和我们在代码中的调用顺序以及传入的参数一致,但实际我们的C代码并不是直接调用了系统调用的socket,而是调用的glibc封装的socket等函数,而这些函数再真正调用socket等系统调用。
Go版追踪结果
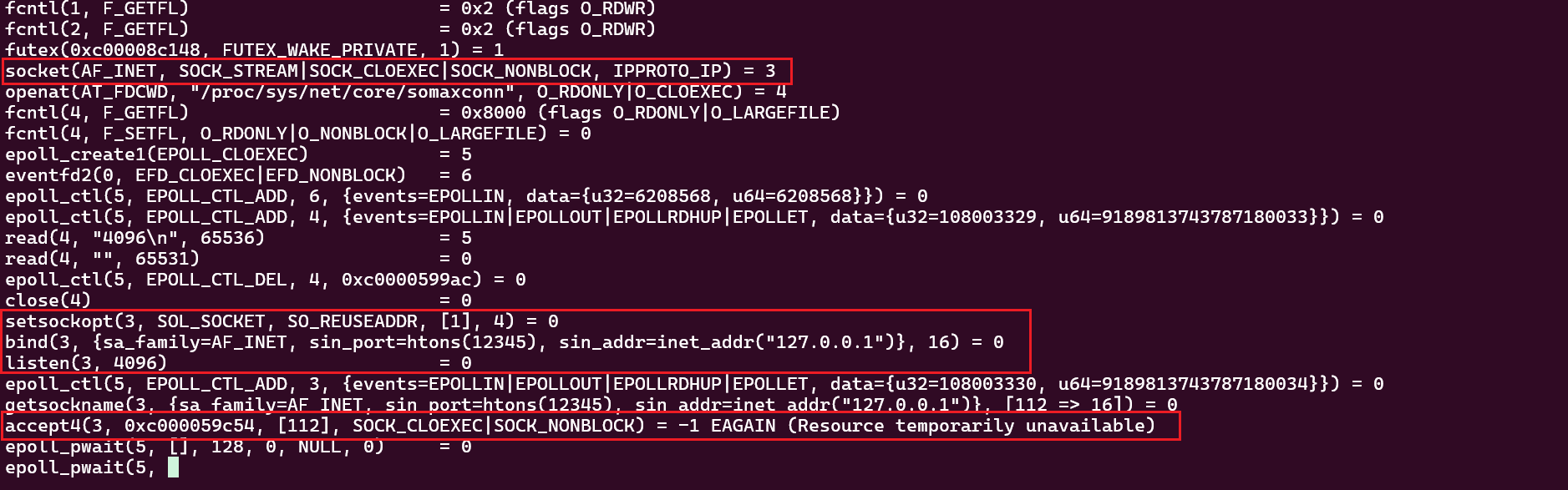
可以看到Go代码编译后执行过程中也调用了socket、bind、listen、accept等系统调用,而且好多参数都不是我们指定的,看到这里是不是觉得还是C更灵活,因为C可以自由指定系统调用的参数。
Rust std::net版追踪结果

追踪结果和Go差不多,也是调用了socket、bind、listen、accept,很多参数也都不是我们自己传入的。
Rust tokio::net版追踪结果

追踪结果和使用std::net实现的版本不太一样,主要是没有看到accept调用,但是多了epool_ctl和futex调用,这也是tokio能支持异步的关键。
说了这么多,其实就是想证明:不管使用什么语言进行网络编程,最终都是殊途同归。所以要想了解Linux的网络原理,就不得不深入研究这些系统调用都干了啥。接下来我们就一步一步来分析socket系统调用干了啥。
socket() 系统调用实现剖析
说明:以下分析使用的Linux内核源码版本为v4.4.302。
socket()系统调用的实现在net/socket.c中,socket()中最关键的动作有两步:
- 调用
sock_create()创建内核socket对象; - 调用
sock_map_fd()将socket对象映射成fd(用于返回给用户态代码);
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
/* Check the SOCK_* constants for consistency. */
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
// 检查、处理参数
flags = type & ~SOCK_TYPE_MASK;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
type &= SOCK_TYPE_MASK;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
// 创建socket对象
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
goto out;
// 为socket对象分配fd
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
if (retval < 0)
goto out_release;
out:
/* It may be already another descriptor 8) Not kernel problem. */
return retval;
out_release:
sock_release(sock);
return retval;
}
从socket()系统调用的实现可以看到:socket()把接收的三个参数(family,type,protocol)全都传递给了sock_create(),另外还把保存socket对象地址的指针sock的地址也传进入了,如果sock_create()成功创建了socket对象,它就会把sock指针指向这个对象,只需要给socket()返回一个表示是否出错的整数值即可。
sock_create分析
下面就看看sock_create()的实现,可以发现sock_create()又加了一个参数,然后调用__sock_create()。这里添加的第一个参数表示当前进程所在的网络命名空间(current指向当前进程task_struct,current->nsproxy->net_ns就是当前进程所在的网络命名空间),这个可以用来做网络隔离,如docker、ip netns就会用到这个。网络命名空间这个参数不能通过调用方通过参数来指定,而是直接取自当前进程所处的命名空间,所以如果在某个网络命名空间创建socket,需要在调用socket之前先调用setns切换到目标命名空间,在socket返回之后,可以再切换到其他命名空间,此时创建的socket已经和目标socket绑定了,无论进程在哪个网络命名空间,都不会影响socket收发数据包。
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
EXPORT_SYMBOL(sock_create);
__sock_create()函数比较长,在研究原理的时候,我们把源码中参数检查、安全及返回值检查相关的代码删掉,只留下关键部分,就得到了下面的代码。可以看到主要分为:
- 调用
sock_alloc()创建一个socket对象; - 根据
family参数确定具体的协议族; - 调用具体的协议族的
create()函数;
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
sock = sock_alloc(); // 创建sock
sock->type = type; // type赋值给sock->type
rcu_read_lock();
pf = rcu_dereference(net_families[family]); // 根据 family 找到对应的协议族
err = pf->create(net, sock, protocol, kern); // 调用目标协议族的create函数
*res = sock; // 把成功创建的sock保存到res中,供调用方使用
return 0;
}
EXPORT_SYMBOL(__sock_create);
我们调用socket()的时候,传入的family是AF_INET,这个family对应的协议族是什么呢?其实就是inet_family_ops,这是inet_init注册的。从__sock_create()中看到会调用对应协议族的create()函数,对于inet_family_ops而言,create函数就是inet_create()。
static const struct net_proto_family inet_family_ops = {
.family = PF_INET, // PF_INET 和 AF_INET 相等
.create = inet_create, // 使用AF_INET作为family调用socket,最终会执行inet_create函数。
.owner = THIS_MODULE,
};
static int __init inet_init(void)
{
(void)sock_register(&inet_family_ops); // 注册协议族
// 初始化inetsw列表
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
// 注册protocol(SOCK_STREAM, SOCK_DGRAM、SOCK_RAW)
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
}
下面就来分析inet_create()干了啥。inet_create()主要逻辑是根据socket()系统调用的第二个参数type和第三个参数protocol来确定具体的传输层(如TCP、UDP、ICMP、RAW)的inet_protosw对象。并创建传输层的sock对象,最终将inet_protosw()的操作和socket对象关联,并将socket对象(struct socket)和传输层sock对象(struct sock)相互绑定。
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
unsigned char answer_flags;
int try_loading_module = 0;
int err;
if (protocol < 0 || protocol >= IPPROTO_MAX)
return -EINVAL;
sock->state = SS_UNCONNECTED; // 初始化socket状态
/* Look for the requested type/protocol pair. */
lookup_protocol:
err = -ESOCKTNOSUPPORT;
rcu_read_lock();
// 根据sock->type(socket的第二个参数)遍历sock->type对应的链表,找到对应的protocol的
// inet_protosw对象
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) { // 优先精确匹配protocol
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}
sock->ops = answer->ops; // 将匹配到的 inet_protosw对象的ops赋值给sock->ops
answer_prot = answer->prot;
answer_flags = answer->flags;
// 分配一个sock,注意是sock不是socket!!!
// struct socket是内核套接字对象
// struct sock是传输层的socket状态
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
inet = inet_sk(sk); // 将struct *sock转换成struct *inet_sk,换个视角看待内存
inet->is_icsk = (INET_PROTOSW_ICSK & answer_flags) != 0;
inet->nodefrag = 0;
if (SOCK_RAW == sock->type) {
inet->inet_num = protocol;
if (IPPROTO_RAW == protocol)
inet->hdrincl = 1;
}
// 关联struct socket和struct sock,并出书画struct sock内部某些字段
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
out:
return err;
}
sock_init_data()的作用是对传输层sock对象的成员初始化,如状态(sk_state)、收发缓冲区大小(sk_sndbuf、sk_rcvbuf)等,以及将socket对象和传输层的sock对象相互关联。
void sock_init_data(struct socket *sock, struct sock *sk)
{
skb_queue_head_init(&sk->sk_receive_queue);
skb_queue_head_init(&sk->sk_write_queue);
skb_queue_head_init(&sk->sk_error_queue);
// 初始化struct sock的一些字段,
sk->sk_send_head = NULL;
init_timer(&sk->sk_timer);
sk->sk_allocation = GFP_KERNEL;
sk->sk_rcvbuf = sysctl_rmem_default;
sk->sk_sndbuf = sysctl_wmem_default;
sk->sk_state = TCP_CLOSE;
sk_set_socket(sk, sock); // sk->sk_socket 指向 sock
if (sock) {
sk->sk_type = sock->type;
sk->sk_wq = sock->wq;
sock->sk = sk; // sock->sk指向sk
} else
sk->sk_wq = NULL;
// ......
sk->sk_rcvtimeo = MAX_SCHEDULE_TIMEOUT;
sk->sk_sndtimeo = MAX_SCHEDULE_TIMEOUT;
}
EXPORT_SYMBOL(sock_init_data);
至此,我们分析完了socket对象的初始化过程。大概思路是:先根据socket()系统调用的第一个参数family找到net_proto_family对象,调用这个对象的create()函数。而net_proto_family的create()函数再根据socket()系统调用的第二、三个参数type和protocol来确定具体的传输层,然后把传输层的一些操作和socket对象关联,另外还创建了一个传输层的sock对象也和socket对象关联起来。至此一个socket对象就算创建并初始化完成。
sock_map_fd分析
socket()系统调用的本质就是创建一个socket对象,但是内核不能直接把这个内核态的对象返回给用户态。我们知道Linux(或者是Unix)的哲学就是一切皆文件,所以socket()系统调用最终会将内核socket对象以文件描述符的形式传递给用户态,这样还有一个好处,即可以使用read()、write()等通用的文件操作。sock_map_fd函数就是做这个工作的。这个函数的逻辑主要分为三步:
- 申请一个新的可用fd;
- 为struct socket分配一个struct file;
- 将struct file和申请的fd关联,并最终返回这个fd;
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
int fd = get_unused_fd_flags(flags); // 申请一个可用的fd
if (unlikely(fd < 0))
return fd;
// 为sock分配一个struct file对象
// struct file的f_op也会被设置为socket专用操作集(socket_file_ops)
newfile = sock_alloc_file(sock, flags, NULL);
if (likely(!IS_ERR(newfile))) {
fd_install(fd, newfile); // 把刚申请的fd和file对象绑定
return fd;
}
put_unused_fd(fd);
return PTR_ERR(newfile);
}
总结
在 Linux 内核中,socket() 系统调用并不是“神秘的黑盒”,而是逐层往下、逐步构建的过程。其核心流程可以总结为:
- 参数解析与标志拆分 — 在 syscall 层处理
type中的SOCK_CLOEXEC和SOCK_NONBLOCK等标志; sock_create()/__sock_create()— 指定网络命名空间、根据协议族选择net_proto_family,并调用对应create方法;- 具体协议族创建 — 比如 AF_INET 的
inet_create(),遍历inetsw匹配协议类型(TCP/UDP/RAW),分配struct sock; - 初始化与绑定 — 通过
sock_init_data()将struct socket与struct sock关联并初始化各字段; - 文件描述符映射 — 通过
sock_map_fd()分配 fd、创建struct file、将 file 和 fd 绑定,使用户态可以通过 fd 操作套接字。
通过这一过程,我们能够看到几个关键的设计思想:
- 对象-句柄分离:用户态看到的只是一个整数 fd,而真正的 socket 结构体在内核中;
- 协议层抽象与接口复用:不同协议(TCP/UDP/RAW)共享统一的处理框架,只在
inet_protosw中区别; - 网络命名空间隔离:套接字从一开始就属于某个
struct net,支持容器、namespace 的网络隔离;
掌握了这条按照层级拆解的思路,以后要深入分析更复杂的网络机制(如 connect()、accept()、send()/recv()、中断处理、TCP 状态机等)就更轻松、系统化。
希望这篇剖析能帮助你揭开socket()系统调用的神秘面纱。